그래프 이론 - 지하철 노선도부터 알고리즘까지
그래프 이론이 뭔데?
아침에 지하철 타고 출근하면서 노선도를 본다. 강남역에서 선릉역 가는 길을 찾는다.
점심시간에 인스타를 켠다. 팔로우 추천이 뜬다. “친구가 팔로우하는 사람” 목록이다.
퇴근길에 구글 지도로 최단 경로를 검색한다. 3가지 경로가 나온다.
이게 전부 그래프 이론이다.
그래프는 점과 선으로 관계를 표현하는 수학이다. 추상적으로 들리지만 매일 쓰고 있다.
개발하면서 그래프를 모르면? 추천 알고리즘 못 만들고, 최단 경로 못 찾고, 의존성 관리 못 한다.
그래프의 기본 구조
노드(Node)와 엣지(Edge)
그래프는 딱 두 가지만 있으면 된다.
- 노드(Node): 점. 역, 사람, 웹페이지 같은 개체를 나타낸다. 정점(Vertex)이라고도 부른다.
- 엣지(Edge): 선. 노드 사이의 관계를 연결한다.
코드로 표현하면?
# 그래프를 인접 리스트로 표현
graph = {
'A': ['B', 'C'], # A는 B, C와 연결됨
'B': ['A', 'D', 'E'], # B는 A, D, E와 연결됨
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
딕셔너리 하나면 끝이다. 생각보다 단순하다.
그래프의 종류
1. 무방향 그래프 vs 방향 그래프
무방향 그래프(Undirected Graph)
양방향으로 갈 수 있다.
- 페이스북 친구 관계: A가 B의 친구면, B도 A의 친구
- 지하철 노선: 강남역에서 신논현역 가면, 반대로도 갈 수 있음

방향 그래프(Directed Graph)
한쪽 방향으로만 간다.
- 인스타 팔로우: A가 B를 팔로우해도, B가 A를 팔로우한다는 보장 없음
- 웹페이지 링크: A에서 B로 링크 걸었다고 B에서 A로 링크 있는 건 아님
# 방향 그래프
directed_graph = {
'A': ['B', 'C'], # A에서 B, C로 갈 수 있음
'B': ['D'], # B에서 D로만 갈 수 있음
'C': [], # C에서는 나가는 엣지 없음
'D': ['A'] # D에서 A로 갈 수 있음 (사이클)
}
2. 가중치 그래프
엣지에 비용이 붙어있다.
- 지도 앱: 두 지점 사이의 거리
- 네트워크: 두 서버 간 전송 시간
- 게임: 두 도시 간 이동 비용

# 가중치 그래프
weighted_graph = {
'A': [('B', 4), ('C', 2)], # A→B 비용 4, A→C 비용 2
'B': [('D', 3), ('E', 1)],
'C': [('F', 5)],
'D': [],
'E': [('F', 2)],
'F': []
}
이게 바로 다익스트라 알고리즘에서 쓰는 구조다.
지하철 노선도
매일 타는 지하철도 그래프다. 서울 지하철 2호선을 코드로 표현하면?
line_2 = {
'강남': ['역삼', '교대'],
'역삼': ['강남', '선릉'],
'선릉': ['역삼', '삼성'],
'삼성': ['선릉', '종합운동장'],
# ... 계속
}
2호선은 순환선이다. 강남역에서 출발해서 계속 타고 가면 다시 강남역으로 돌아온다.
이걸 그래프 용어로 사이클(Cycle)이라고 한다. 시작점으로 돌아올 수 있는 경로가 있으면 사이클이다.
그래프 탐색 알고리즘
그래프에서 특정 노드를 찾거나 모든 노드를 방문하려면?
두 가지 방법이 있다.
DFS (Depth-First Search, 깊이 우선 탐색)
일단 끝까지 파고들고 본다.
미로 탈출할 때 한 방향으로 쭉 가다가 막히면 되돌아오는 방식.
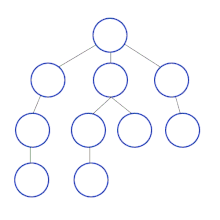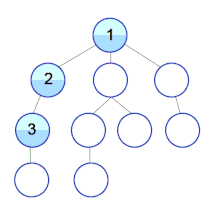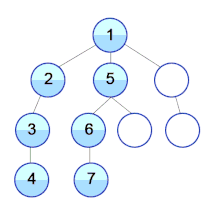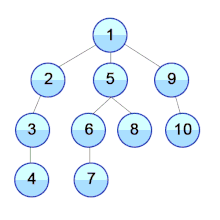
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start, end=' ')
for neighbor in graph[start]:
if neighbor not in visited:
dfs(graph, neighbor, visited)
return visited
# 실행
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
dfs(graph, 'A') # 출력: A B D E F C
재귀로 구현하면 간단하다. 스택 자료구조를 쓴다고 보면 된다.
BFS (Breadth-First Search, 너비 우선 탐색)
가까운 것부터 차례대로 탐색한다.
물결이 퍼지듯이 한 단계씩 확장해나간다.

from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
visited.add(start)
while queue:
node = queue.popleft()
print(node, end=' ')
for neighbor in graph[node]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
# 실행
bfs(graph, 'A') # 출력: A B C D E F
큐(Queue)를 쓴다. 먼저 들어간 노드를 먼저 처리한다.
DFS vs BFS 언제 뭘 쓰나?
헷갈린다. 둘 다 그래프 탐색인데 언제 뭘 써야 하나?
| 상황 | 알고리즘 | 이유 |
|---|---|---|
| 최단 경로 찾기 (가중치 없음) | BFS | 가까운 것부터 탐색하니까 |
| 경로 존재 여부 확인 | DFS | 빠르게 끝까지 가봄 |
| 모든 경로 탐색 | DFS | 재귀로 백트래킹 쉬움 |
| 레벨별 탐색 | BFS | 단계별로 퍼져나감 |
간단하게 정리하면 “최단”이 나오면 BFS, “존재”나 “모든”이 나오면 DFS다.
문제에서 “최단 거리” 보이면 BFS 먼저 떠올려라. 90%는 맞다.
최단 경로 알고리즘
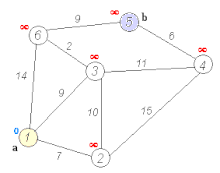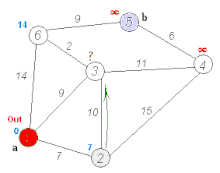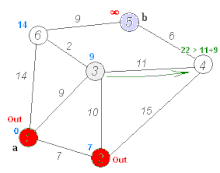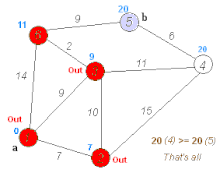
다익스트라(Dijkstra) 알고리즘
가중치가 있는 그래프에서 최단 경로를 찾는다.
구글 지도가 이걸 쓴다 (정확히는 개선된 버전).
import heapq
def dijkstra(graph, start):
distances = {node: float('inf') for node in graph}
distances[start] = 0
pq = [(0, start)] # (거리, 노드)
while pq:
current_distance, current_node = heapq.heappop(pq)
if current_distance > distances[current_node]:
continue
for neighbor, weight in graph[current_node]:
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(pq, (distance, neighbor))
return distances
# 실행
weighted_graph = {
'A': [('B', 4), ('C', 2)],
'B': [('D', 3), ('E', 1)],
'C': [('F', 5)],
'D': [],
'E': [('F', 2)],
'F': []
}
result = dijkstra(weighted_graph, 'A')
print(result) # A에서 각 노드까지 최단 거리
우선순위 큐(힙)를 쓴다. 가장 가까운 노드부터 처리한다.
시간 복잡도는 O(E log V). E는 엣지 개수, V는 노드 개수.
소셜 네트워크 분석
인스타나 페이스북 “친구 추천” 본 적 있지? 그게 그래프 탐색이다.
친구 관계를 그래프로 표현하면?
social_network = {
'철수': ['영희', '민수', '지영'],
'영희': ['철수', '민수'],
'민수': ['철수', '영희', '지영', '동수'],
'지영': ['철수', '민수'],
'동수': ['민수']
}

친구 추천 알고리즘
로직은 간단하다. “내 친구의 친구” 중에서 내가 모르는 사람을 추천한다.
def recommend_friends(network, user):
friends = set(network[user])
friends_of_friends = set()
for friend in friends:
for fof in network[friend]:
if fof != user and fof not in friends:
friends_of_friends.add(fof)
return friends_of_friends
print(recommend_friends(social_network, '철수'))
# 출력: {'동수'}
실제 페이스북은 훨씬 복잡한 알고리즘을 쓰지만, 기본 원리는 이거다.
사이클 탐지
사이클이 있으면 안 되는 경우가 있다.
- 순환 참조: 객체 A가 B를 참조하고, B가 A를 참조하면? JSON 직렬화 실패
- 교착 상태: 프로세스 A가 B를 기다리고, B가 A를 기다리면? 무한 대기
- 의존성 순환: 패키지 A가 B에 의존하고, B가 A에 의존하면? 설치 불가
그래서 사이클을 탐지해야 한다.
def has_cycle_dfs(graph):
visited = set()
rec_stack = set() # 현재 재귀 스택
def dfs(node):
visited.add(node)
rec_stack.add(node)
for neighbor in graph.get(node, []):
if neighbor not in visited:
if dfs(neighbor):
return True
elif neighbor in rec_stack:
return True # 사이클 발견!
rec_stack.remove(node)
return False
for node in graph:
if node not in visited:
if dfs(node):
return True
return False
# 테스트
cycle_graph = {
'A': ['B'],
'B': ['C'],
'C': ['A'] # A → B → C → A (사이클)
}
print(has_cycle_dfs(cycle_graph)) # True
재귀 스택에 이미 있는 노드를 다시 만나면 사이클이다.
위상 정렬 (Topological Sort)
대학교 수강신청할 때 선수과목 봤지? 그게 위상 정렬이다.
의존성 순서를 정렬하는 알고리즘이다.
예를 들어, 이런 수강 순서가 있다면:
프로그래밍기초 → 자료구조 → 알고리즘
이산수학 → 알고리즘
어느 과목부터 들어야 할까? 위상 정렬이 답을 준다.

from collections import deque, defaultdict
def topological_sort(graph):
in_degree = defaultdict(int)
# 진입 차수 계산
for node in graph:
for neighbor in graph[node]:
in_degree[neighbor] += 1
# 진입 차수가 0인 노드부터 시작
queue = deque([node for node in graph if in_degree[node] == 0])
result = []
while queue:
node = queue.popleft()
result.append(node)
for neighbor in graph[node]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
return result
# 수강 과목 의존성
courses = {
'프로그래밍기초': ['자료구조'],
'이산수학': ['알고리즘'],
'자료구조': ['알고리즘'],
'알고리즘': []
}
print(topological_sort(courses))
# 출력: ['프로그래밍기초', '이산수학', '자료구조', '알고리즘']
npm install 할 때 패키지 설치 순서를 정하는 게 바로 이거다. React 설치하기 전에 React가 의존하는 패키지들부터 설치한다.
개발하면서 만나는 그래프들
그래프는 교과서에만 있는 게 아니다. 개발하면서 매일 쓴다.
데이터베이스 쿼리 최적화
SQL JOIN도 그래프다. 테이블 간 관계를 그래프로 표현하고 최적 경로를 찾는다. 5개 테이블 JOIN하는 순서에 따라 성능이 10배 차이난다.
웹 크롤링
웹페이지 간 링크가 그래프다. BFS로 크롤링하면 가까운 페이지부터 차례대로 수집한다.
# 간단한 웹 크롤러 구조
def crawl(start_url):
visited = set()
queue = deque([start_url])
while queue:
url = queue.popleft()
if url in visited:
continue
visited.add(url)
links = get_links(url) # 페이지에서 링크 추출
queue.extend(links)
추천 시스템
쿠팡이나 넷플릭스 추천도 그래프다. 상품 간 연관 관계를 그래프로 표현한다.
“이 상품을 본 사람들이 함께 본 상품” → 상품 노드를 2단계 탐색한 결과다.
네트워크 라우팅
인터넷 패킷도 그래프를 따라 이동한다. 서울에서 뉴욕까지 패킷이 어느 서버를 거쳐갈지 결정하는 게 최단 경로 알고리즘이다.
정리
그래프 이론을 처음 배울 때는 “이게 어디에 쓰여?”라고 생각했다.
근데 개발하다 보면 매일 그래프를 쓰고 있다.
아침에 타는 지하철 노선도? 그래프다.
인스타 팔로우 추천? 그래프 탐색이다.
npm install 할 때 패키지 순서? 위상 정렬이다.
구글 지도 최단 경로? 다익스트라다.
DFS/BFS만 제대로 알면 웬만한 탐색 문제는 다 풀린다.
다익스트라까지 알면 최단 경로 문제도 손쉽게 해결된다.
그래프는 어려운 수학이 아니다. 관계를 표현하는 도구다.
개발하면서 “아, 이거 그래프로 풀면 되겠네?”하고 바로 떠올릴 수 있으면 성공이다.